|
Biodiversity Information Science and Standards : Conference Abstract
|
|
Corresponding author: Emily Jane McTavish (ejmctavish@ucmerced.edu)
Received: 14 May 2019 | Published: 21 Jun 2019
© 2019 Emily Jane McTavish
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: McTavish E (2019) Linking Biodiversity Data Using Evolutionary History. Biodiversity Information Science and Standards 3: e36207. https://doi.org/10.3897/biss.3.36207
|
|
Abstract
All life on earth is linked by a shared evolutionary history. Even before Darwin developed the theory of evolution, Linnaeus categorized types of organisms based on their shared traits. We now know these traits derived from these species’ shared ancestry. This evolutionary history provides a natural framework to harness the enormous quantities of biological data being generated today.
The Open Tree of Life project is a collaboration developing tools to curate and share evolutionary estimates (phylogenies) covering the entire tree of life (
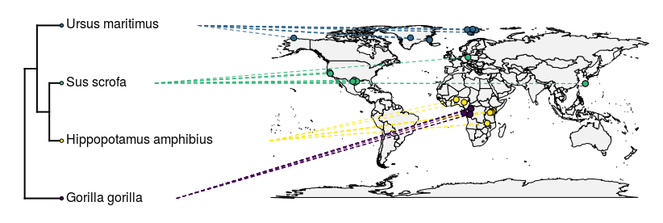
Example linking phylogenetic relationships accessed from the Open Tree of Life with specimen location data from Global Biodiversity Information Facility.
For example, a recent publication by
In order to support innovative science, large scale digital data resources need to facilitate data linkage between resources, and address researchers' data quality and provenance concerns. I will present the model that the Open Tree of Life is using to provide evolutionary data at the scale of the entire tree of life, while maintaining traceable provenance to the publications and taxonomies these evolutionary relationships are inferred from. I will discuss the hurdles to adoption of these large scale resources by researchers, as well as the opportunities for new research avenues provided by the connections between evolutionary inferences and biodiversity digital databases.
Keywords
evolution, phylogeny, taxonomy, interoperability
Presenting author
Emily Jane McTavish
Presented at
Biodiversity_Next 2019
Funding program
NSF Division Of Biological Infrastructure, Advances in Biological Informatics #1759846
Grant title
"Cultivating a sustainable Open Tree of Life"
References
-
Catalogue of Life Plus: innovating the CoL systems as a foundation for a clearinghouse for names and taxonomy.Biodiversity Information Science and Standards2https://doi.org/10.3897/biss.2.26922
-
rgbif: Interface to the Global 'Biodiversity' Information Facility API.0.99. URL: https://CRAN.R-project.org/package=rgbif
-
Synthesis of phylogeny and taxonomy into a comprehensive tree of life.Proceedings of the National Academy of Sciences112(41):12764‑12769. https://doi.org/10.1073/pnas.1423041112
-
For comparing phylogenetic diversity among communities, go ahead and use synthesis phylogenies.bioRxivhttps://doi.org/10.1101/370353
-
How and Why to Build a Unified Tree of Life.BioEssays39(11). https://doi.org/10.1002/bies.201700114
-
rotl: an R package to interact with the Open Tree of Life data.Methods in Ecology and Evolutionn/a-n/a‑n/a-n/a. https://doi.org/10.1111/2041-210X.12593
-
Automated assembly of a reference taxonomy for phylogenetic data synthesis.Biodiversity Data Journalhttps://doi.org/10.3897/BDJ.5.e12581
-
phytools: an R package for phylogenetic comparative biology (and other things).Methods in Ecology and Evolution3(2):217‑223. https://doi.org/10.1111/j.2041-210X.2011.00169.x
-
Most species are not limited by an Amazonian river postulated to be a border between endemism areas.Scientific Reports8(1). https://doi.org/10.1038/s41598-018-20596-7