|
Biodiversity Information Science and Standards : Conference Abstract
|
|
Corresponding author: Roderic Page (roderic.page@glasgow.ac.uk)
Received: 30 Mar 2019 | Published: 13 Jun 2019
© 2019 Roderic Page
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Page R (2019) Text-mining BHL: towards new interfaces to the biodiversity literature. Biodiversity Information Science and Standards 3: e35013. https://doi.org/10.3897/biss.3.35013
|
|
Abstract
The taxonomic literature is one of the largest resources of information on biodiversity, both current and in the past. Unlike many scientific disciplines this literature remains perpetually relevant as successive taxonomic work builds upon those earlier foundations. Projects such as the Biodiversity Heritage Library (BHL) have greatly increased access to that literature, as have numerous independent digitisation efforts by museums, herbaria, and publishers. But the focus of this access has been human readers, with limited use of text mining tools, mostly focussed on extracting taxonomic names. This talk explores other kinds of data that can be extracted from text on BHL and elsewhere, focusing on taxonomic names, geographic localities and specimen codes in the context of the BioStor project (https://biostor.org,
The problem of finding taxonomic names in text has been well studied (e.g.,
In addition to taxonomic names, a typical taxonomic paper often contains specimen codes. Extracting these from text and linking them to digital representations, such as occurrence records in GBIF, opens up the possibility to provide detailed provenance for occurrence data, as well as citation-based metrics for the utility of natural history collections.
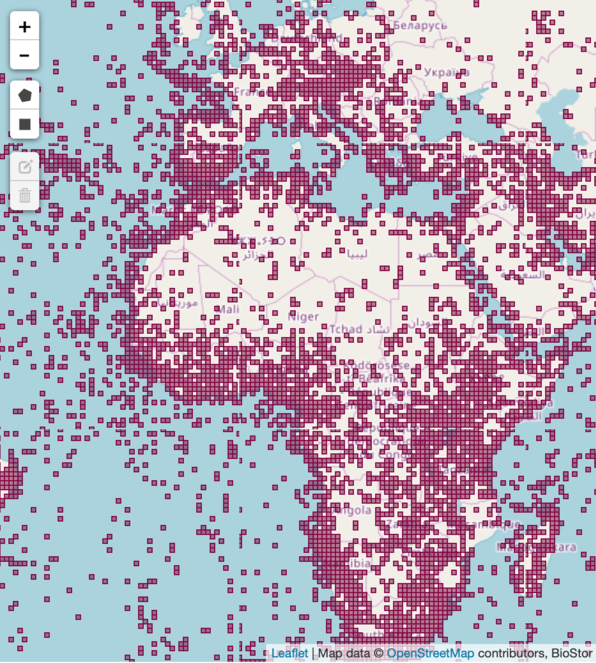
Taxonomic papers are also often rich in geographic information. A simple method for extracting locality information from text is to search for latitude and longitude coordinates, and BioStor currently does this. To date some 83,000 individual point localities have been extracted (Fig.
A general framework for handling data on taxonomic names, specimens, and geographic localities in text is to treat them as annotations (
Keywords
text mining, BHL, BioStor, taxonomic names, specimens, geocoding
Presenting author
Roderic Page
References
-
NetiNeti: discovery of scientific names from text using machine learning methods.BMC Bioinformatics13(1):211‑211. https://doi.org/10.1186/1471-2105-13-211
-
A Text Mining-Based Framework for Constructing an RDF-Compliant Biodiversity Knowledge Repository.Information Management and Big Data. [ISBN978-3-319-55209-5]. https://doi.org/10.1007/978-3-319-55209-5_3
-
Discovering Ecologically Relevant Knowledge from Published Studies through Geosemantic Searching.BioScience63(8):674‑682. https://doi.org/10.1525/bio.2013.63.8.10
-
Extracting scientific articles from a large digital archive: BioStor and the Biodiversity Heritage Library.BMC Bioinformatics12(1):187‑187. https://doi.org/10.1186/1471-2105-12-187
-
Towards a biodiversity knowledge graph.Research Ideas and Outcomes2:e8767‑e8767. https://doi.org/10.3897/rio.2.e8767
-
BioNames: linking taxonomy, texts, and trees.PeerJ1:e190‑e190. https://doi.org/10.7717/peerj.190